ETLプロセスの説明
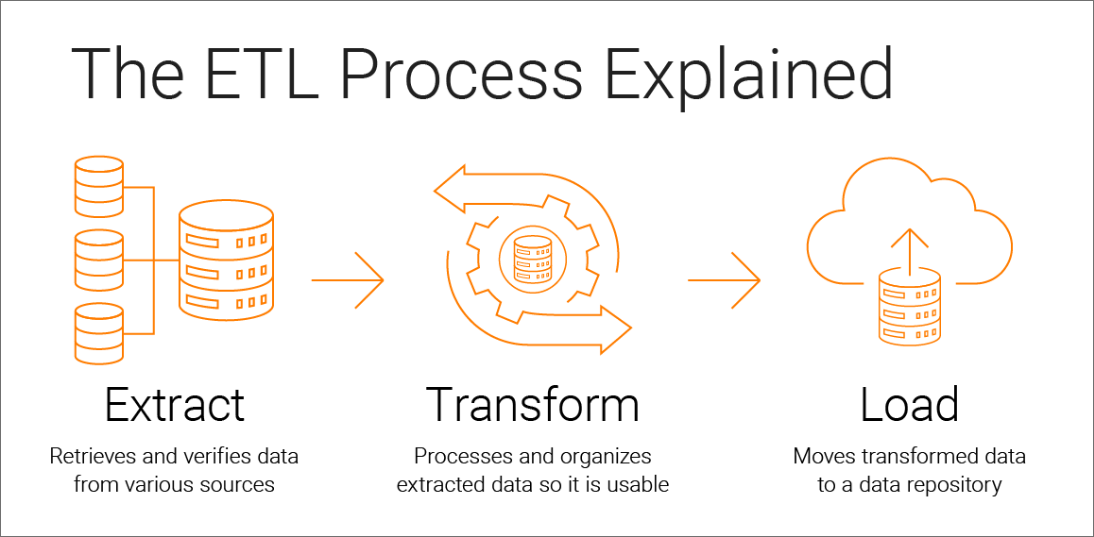
ETLでは、3つのステップを通じて、1つまたは複数のソースにあるデータをターゲット(データベース、データウェアハウス、データストア、データレイクなど)に移動します。以下に簡単な概要を示します。
抽出
「抽出、変換、ロード」のステップ1は抽出です。1つまたは複数のデータソースからデータを収集します。収集したデータを一時的なストレージに保管し、次の2つのステップを実行します。
抽出時に、検証ルールが適用されます。これにより、データがターゲットの要件を満たしているかどうかを確認します。検証の結果、不合格となったデータは拒否され、次のステップには進みません。
変換
変換フェーズでは、用途に合わせてデータの値と構造を処理します。変換の目的は、ステップ3に進む前に、すべてのデータを統一のスキーマに合わせることです。
一般的な変換として、アグリゲータ、データマスキング、式、ジョイナー、フィルター、ルックアップ、ランク、ルーター、ユニオン、XML、正規化、H2R、R2H、Webサービスなどがあります。変換により、データを正規化、標準化、フィルタリングできます。また、アナリティクスや業務、その他の下流の作業でデータを利用できるようになります。
ロード
ステップ3のロードフェーズでは、変換したデータを永続的なターゲットシステムに移動します。ここでいうターゲットシステムとは、オンプレミスまたはクラウドにあるデータベース、データウェアハウス、データストア、データハブ、データレイクなどを指します。すべてのデータがロードされると、プロセスは完了となります。
多くの組織が、ETLプロセスを定期的に実行することで、データウェアハウスを最新の状態に保っています。
従来型ETLとクラウドETLの違い
従来型ETL
従来型ETLは、社内の経験豊富なIT部門が管理する、オンプレミスにあるデータを移動するためのプロセスです。IT部門が社内のデータパイプラインとデータベースを作成して管理します。
通常、従来型ETLでは特定のスケジュールに沿ってバッチ処理を通じてデータを移動します。バッチ処理のスケジュールは、ネットワークトラフィックが少ないタイミングに合わせて設定するのが理想です。従来型ETLでは、リアルタイム分析を実行するのは困難です。必要なデータアナリティクスを抽出するためには、IT部門が複雑なカスタマイズ作業に労力を費やして、品質管理を厳密に行う必要があるためです。また、従来型ETLシステムでは、データ量の急増に対応するのも困難です。そのため、「詳細なデータ」か「高速パフォーマンス」のいずれかを選択することを迫られます。
クラウドETL
クラウドETLでは、あらゆるタイプのデータソースから構造化データと非構造化データを抽出できます。オンプレミスにあるデータも、クラウドデータウェアハウスにあるデータも抽出できます。データを抽出したら、それを結合および変換し、中央の場所にロードします。ロードしたデータにはオンデマンドでアクセスできます。
クラウドETLは通常、幅広い用途のために、アナリスト、エンジニア、意思決定者に大量のデータを提供する際に使用します。
ETLとELTの違い
ETL(抽出、変換、ロード)とELT(抽出、ロード、変換)は、異なる別々のデータ統合プロセスです。同じステップを異なる順序で実行することで、さまざまなデータマネジメントに対応できます。
ELTとETLはいずれも、各種データソースから未加工データを抽出します。ここでいうデータソースとは、エンタープライズリソースプランニング(ERP)プラットフォーム、ソーシャルメディアプラットフォーム、IoTデータ、スプレッドシートなどです。ELTでは、未加工データをターゲット(データウェアハウス、データレイク、リレーショナルデータベース、データストア)に直接ロードします。データ変換は、必要に応じて、ロード後に実行できます。また、ソースにあるデータセットをロードすることもできます。ETLでは、データを抽出した後、データを定義および変換して、データの品質と整合性を高めてから、変換したデータをデータリポジトリにロードします。そのリポジトリにアクセスすることでデータを使用できます。
では、ETLとELTのどちらを選択すべきなのでしょう。比較的小規模のデータリポジトリを作成して、それを長期にわたって保持し、頻繁にアップデートする必要がない場合は、ETLを検討しましょう。大容量のデータセットを扱い、ビッグデータをリアルタイムで管理する必要がある場合は、ELTが適しています。
詳しくは、ブログ記事の一節「What is the difference between ETL and ELT?(ETLとELTの違いとは)」をご覧ください。
ETLパイプラインとデータパイプラインの違い
「ETLパイプライン」と「データパイプライン」という用語は、同じ意味で使用されることがあります。しかし、両者には基本的な違いがあります。
データパイプラインとは、各種ソースのデータをインジェストして、ターゲットリポジトリに移動するための一連のプロセス、ツール、アクションです。相互接続されたソースシステム内で追加のアクションやプロセスフローが発生する場合があります。
ETLパイプラインの場合、変換したデータがデータベースまたはデータウェアハウスに格納されます。そのデータをビジネスアナリティクスやインサイト用に使用できます。
さまざまなタイプのETLパイプライン
ETLデータパイプラインは、レイテンシに基づいて分類されます。最も一般的なのは、バッチ処理またはリアルタイム処理のパイプラインです。
バッチ処理パイプライン
バッチ処理パイプラインは、データを定期的に収集、変換し、クラウドデータウェアハウスに移動する従来型のアナリティクスやビジネスインテリジェンスに使用します。
サイロ化したソースにある大量のデータをクラウドデータレイクやデータウェアハウスに迅速に展開できます。また、データ処理ジョブのスケジュールを設定することで、人間の介入を最小限に抑制できます。ETLをバッチ処理で行う場合、「バッチウィンドウ」と呼ばれる時間枠内にデータが収集、格納されます。バッチ処理は、大量のデータや反復的なタスクをより効率的に管理したい場合に使用されます。
リアルタイム処理パイプライン
リアルタイム処理データパイプラインでは、さまざまなストリーミングソースから構造化データと非構造化データをインジェストできます。ここでいうストリーミングソースとは、IoT、コネクテッドデバイス、ソーシャルメディアフィード、センサーデータ、モバイルアプリケーションなどです。スループットの優れたメッセージングシステムにより、データを正確にキャプチャできます。
Sparkストリーミングなどのリアルタイム処理エンジンを使用して、データ変換を実行します。このデータは、リアルタイムアナリティクス、GPS位置追跡、不正検出、予知保全、ターゲットを絞ったマーケティングキャンペーン、プロアクティブなカスタマーケアなどのアプリケーション機能で活用できます。
ETLからELTに移行する際の課題
クラウドデータウェアハウスとデータレイクの処理能力が向上したことで、データ変換の方法が変化しました。この変化により、多くの組織がETLからELTに移行しています。しかし、この移行は必ずしも容易ではありません。
ETLのマッピングは、さまざまなデータの種類、データソース、頻度、形式をサポートできるだけの堅牢性を備えています。これらのマッピングをELTに対応する形式に変換するには、フロントエンドを壊すことなくデータを処理し、プッシュダウンオプティマイゼーションをサポートできる企業データプラットフォームが必要です必要なエコシステム/データウェアハウス固有のコードを生成できないプラットフォームを使用している場合、開発者は高度な変換を実行するためのクエリを手作業でコーディングしなければなりません。このような作業は、労力とコストがかかり、複雑で、ストレスとなります。このため、ETLのマッピングを複製してこれをELTパターンで実行できる、使いやすいインターフェイスを備えたプラットフォームを選択することが重要です。
ETLのメリット
ETLツールは、データプラットフォームと連携して、さまざまなデータマネジメント使用事例(データ品質、データガバナンス、仮想化、メタデータなど)に対応できます。ETLには、次のようなメリットがあります。
過去から現在までのビジネス状況を把握
ETLとエンタープライズ データウェアハウス(保存データ)を併用することで、過去のデータと新しいプラットフォーム/アプリケーションから収集したデータを組み合わせて、過去から現在までに至るビジネス状況を把握できます。
クラウドデータ移行を簡素化
データをクラウドデータレイクまたはクラウドデータウェアハウスに移行することで、データのアクセス性、アプリケーションの拡張性、セキュリティを強化できます。企業は、業務を改善するために今まで以上にクラウド統合を活用するようになっています。
ビジネスの統合ビューを確立
オンプレミスのデータベースやデータウェアハウス、SaaSアプリケーション、IoTデバイス、ストリーミングアプリケーションなどのソースからクラウドデータレイクにデータをインジェストして、同期できます。これにより、ビジネスの360度ビューを確立できます。
あらゆるデータから、あらゆるレイテンシでビジネスインテリジェンスを引き出す
今日の企業は、さまざまなタイプのデータを分析しなければなりません。これには、構造化、半構造化、非構造化などのタイプが挙げられます。また、バッチ、リアルタイム、ストリーミングなど、複数のソースから収集したデータを分析する必要があります。
ETLツールを使用すれば、データから実用的なインサイトを簡単に引き出すことができます。その結果、新たなビジネスチャンスを特定して、意思決定を改善できます。
信頼できる高品質データを獲得して意思決定に活用
ETLツールを使用して、データを変換しながら、データリネージとトレーサビリティをデータのライフサイクル全体にわたって維持します。これにより、データを実践的に活用するユーザー(データサイエンティスト、データアナリスト、業務担当者など)が信頼できるデータにアクセスできます。
ETLにおける人工知能(AI)と機械学習(ML)
AI/MLベースのETLにより、重要なデータ業務を自動化し、分析用データの品質を確保できます。そして、そのデータから信頼できるインサイトを引き出して、意思決定に活用できます。また、他のデータ品質ツールと組み合わせることで、独自のニーズに適したデータを獲得できます。
ETLとデータの民主化
ETLを必要とするのは、技術担当者だけではありません。業務担当者もデータに簡単にアクセスして、そのデータを各自のシステム、サービス、アプリケーションと統合しなければなりません。ETLプロセスの設計と実行にAIを組み込むことで、業務担当者もETLを容易に活用できるようになります。AI/ML対応のETLツールは、過去のデータから学習し、業務担当者のシナリオに沿って、再利用可能な最適なコンポーネント(データマッピング、マプレット、データ変換、パターン、コンフィグレーションなど)を提案します。その結果、チームの生産性が向上します。さらに、自動化により、人間の介入が少なくなるため、容易にポリシーを遵守できます。
ETLパイプラインを自動化
AIベースのETLツールにより、繰り返し発生するデータエンジニアリングタスクを自動化することで、労力と時間を節約できます。これにより、データマネジメントの効率性を高めて、データ配信を高速化できます。さらに、データウェアハウジング用のデータのインジェスチョン、処理、統合、エンリッチ化、準備、マッピング、定義、カタログ化を自動化できます。
ETLでAI/MLモデルを運用化
クラウドETLツールにより、AI/ML用データパイプラインに必要となる大量のデータを効率的に処理できます。適切なツールがあれば、MLトランスフォーメーションをデータマッピングにドラッグアンドドロップできます。これにより、データサイエンスのワークロードの堅強性、効率性、保守容易性が向上します。また、AI搭載ETLツールを使用すれば、継続統合/継続配信(CI/CD)、DataOps、MLOpsを容易に導入して、データパイプラインを自動化できます。
Changed Data Capture(変更データキャプチャ)でデータベースを複製
ETLにより、さまざまなソースデータベース(MySQL、PostgreSQL、Oracleなど)からクラウドデータウェアハウスにデータを複製して自動同期できます。変更データキャプチャを使用して、プロセスを自動化し、変更のあったデータセットのみを更新することで、時間を短縮して、効率性を改善できます。
ETLによるデータ処理でビジネスの敏捷性を向上
ETLにより、データの収集、準備、結合に必要な労力を軽減できるため、チームの敏捷性が向上します。また、AIベースのETLを通じて自動化することで、生産性が向上します。データプロフェッショナルは、コードやスクリプトを記述することなく、必要なデータに、必要な場所でアクセスできます。これにより、貴重な時間とリソースを節約できます。
クラウドETLの価格設定:考慮すべき点
ETLにより、ソースとターゲットの間でデータを共有できます。具体的には、データをコピーして、変換し、別の場所に保存することになります。したがって、オンプレミスETLとクラウドETLのどちらを使用するかによって、価格やリソースは変わることになります。
オンプレミスETLの場合、購入済みのリソースを使用します。年間予算とキャパシティプランニングに従って、データをオンプレミスに保存します。しかし、クラウドETLの場合、ストレージコストが別途発生します。従量制の価格設定のため、別の場所にデータをインジェストして保存するたびにコストが発生することになります。そのため、適切な計画がなければ、大きな負担となる可能性があります。
クラウドETLを使用する場合、ストレージ/処理の合計コストとデータ保持要件を見極めることが重要です。これにより、使用事例に応じて適切な統合プロセスを確実に選択できます。また、適切なクラウドベース統合パターンとデータ保持ポリシーを通じて、コストを最適化できます。
ETLの業界別使用事例
ETLは、データ統合の方法として、幅広い業界で不可欠な存在となっています。ETLにより、業務の生産性の向上、顧客ロイヤリティの改善、オムニチャネル体験の提供、新たな収益源やビジネスモデルの発見などが可能になります。
医療業界におけるETL
医療機関は、総体的なデータマネジメントアプローチでETLを活用しています。組織全体で異種データを統合することで、臨床プロセスとビジネスプロセスを加速しています。また同時に、加入者、患者、医療従事者の体験を改善しています。
官公庁・公共機関におけるETL
官公庁・公共機関は、厳しい予算での運営を強いられています。そのため、ETLを使用して必要なインサイトを獲得することで、業務効率を最大化しています。限られたリソースでサービスを提供するためには、効率性の向上が不可欠です。データ統合により、政府機関はデータと資金を最大限活用できるようになります。
製造業界におけるETL
製造業界のリーディング企業は、さまざまな理由に基づいてデータを変換しています。ETLにより、業務の生産性を最適化することや、サプライチェーンの透明性、レジリエンス、応答性を確保することなどが可能になります。また、オムニチャネル体験を改善し、法規制へのコンプライアンスも確立できます。
金融サービス業界におけるETL
金融機関は、ETLを使用して透明かつ総体的で保護されたデータにアクセスすることで、売上を拡大して、パーソナライズした顧客体験を提供しています。また、不正取引の検出や防止も行っています。さらに、新規および既存の規制に準拠しながら、合併と買収の価値を迅速に実現しています。これにより、顧客を正確に理解して、顧客固有のニーズに適したサービスを提供できます。
データ統合のためのインフォマティカソリューションとクラウドETL
インフォマティカが提供する業界先進のデータ統合ツール/ソリューションにより、包括的かつコーディング不要でAIを活用したクラウドネイティブなデータ統合が実現します。Amazon Web Services、Microsoft Azure、Google Cloud、Snowflake、Databricksなどのマルチクラウド環境全体にわたって、データパイプラインを作成できます。タイプ、量、速度、レイテンシを問わず、あらゆるデータをインジェスト、エンリッチ化、変換、準備、拡張、共有して、データ統合やデータサイエンスのイニシアチブを推進できます。エンドツーエンドのデータパイプラインを迅速に開発および運用化し、レガシーアプリケーションをAI向けにモダナイズできます。
ETLを使い始める
Informatica Cloud Data Integrationの無料体験版にご登録ください。すぐに使い始められる幅広い接続性、コーディング不要、あらかじめ組み込まれた高度なトランスフォーメーションとオーケストレーションなどの特長を備えたソリューションを通じて、いかに迅速にデータパイプラインを作成できるかを直接ご体験いただけます。インフォマティカのツールは、シングルクラウド、マルチクラウド、オンプレミスなどの環境を問わず、簡単に統合して使用できるデータ統合ツールです。





